(Web Crawling) - 파일 저장하기
파이썬 웹 크롤링(Web Crawling) - 4. 크롤링 심화
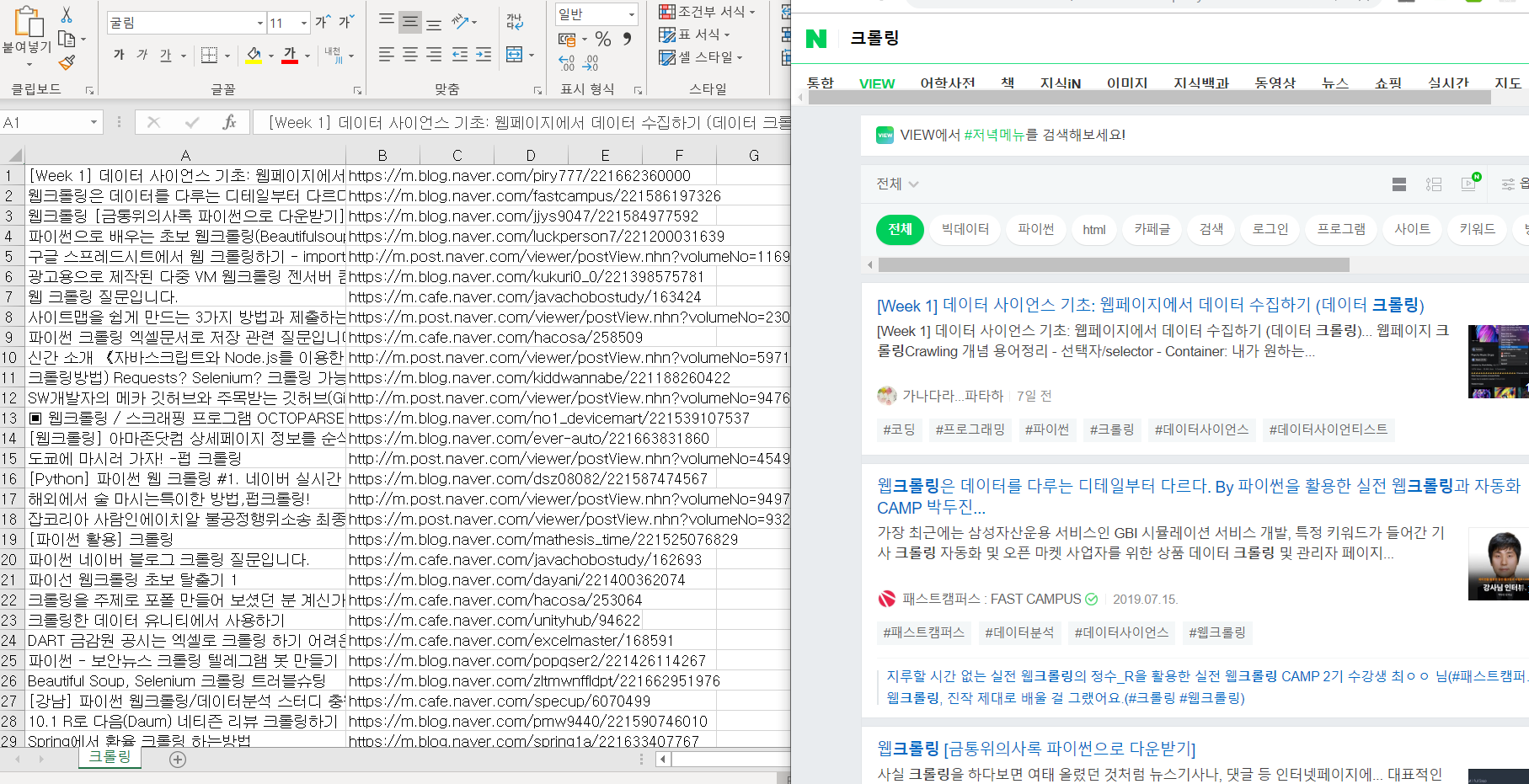
예제 1) 네이버 블로그 검색결과 CSV(엑셀) 파일로 저장하기
1 | import csv |
크롤링을 검색해서 나온 30개의 결과 값을 저장했습니다.
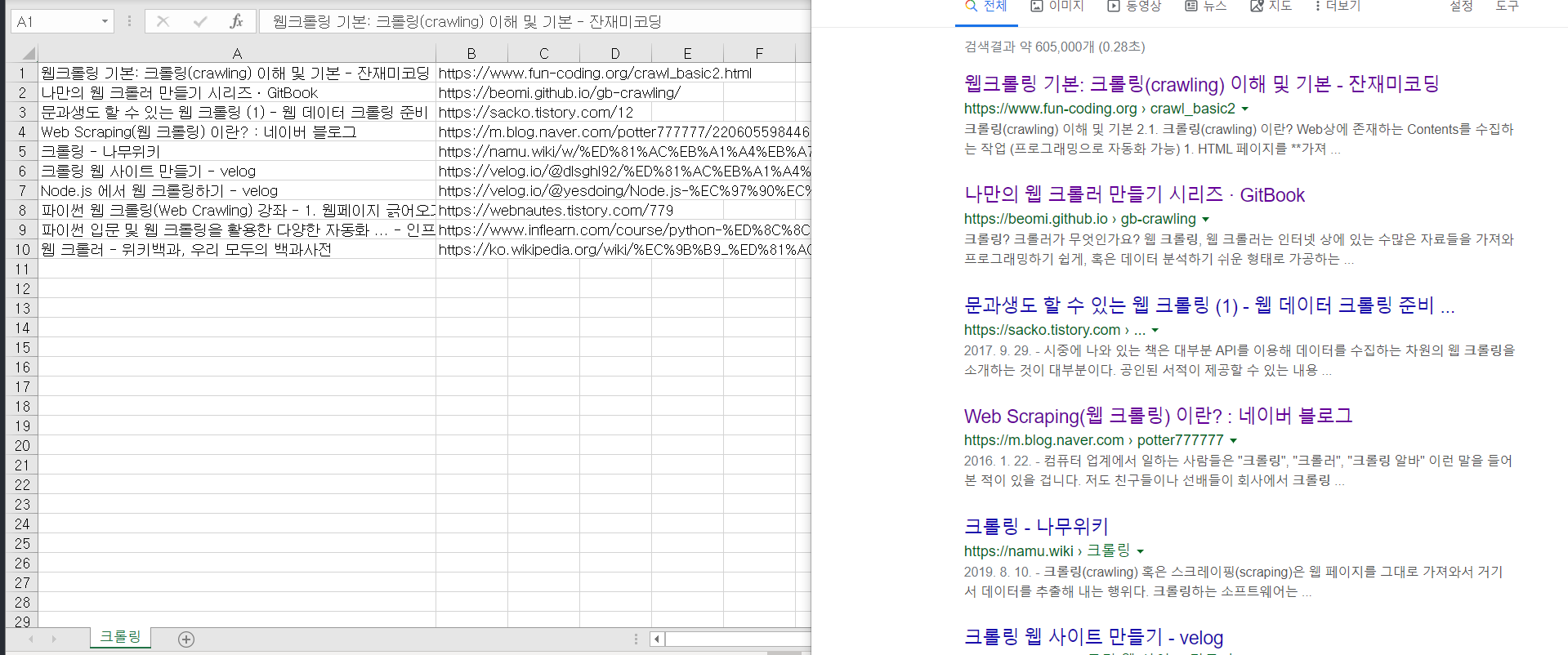
예제 2) 구글 검색결과 CSV(엑셀) 파일로 저장하기
1 | import csv |
크롤링을 검색해서 나온 10개의 결과 값을 저장했습니다.(구글)
Related Articles
Comment
1 | import csv |
1 | import csv |