from urllib.request import urlopen from bs4 import BeautifulSoup as bs import urllib.parse
# 네이버 검색 후 검색 결과 baseUrl = 'https://search.naver.com/search.naver?where=post&sm=tab_jum&query=' plusUrl = input('검색어를 입력하세요 : ') # 한글 검색 자동 변환 url = baseUrl + urllib.parse.quote_plus(plusUrl) html = urlopen(url) bsObject = bs(html, "html.parser")
# 조건에 맞는 파일을 다 출력해라 title = bsObject.find_all(class_='sh_blog_title')
for i in title: print(i.attrs['title']) print(i.attrs['href']) print()
i = input('몇 페이지를 크롤링 할까요? : ') lastPage = int(i) * 10 - 9 while pageNum < lastPage + 1: url = f'https://search.naver.com/search.naver?date_from=&date_option=0&date_to=&dup_remove=1&nso=&post_blogurl=&post_blogurl_without=&query={plusUrl}&sm=tab_pge&srchby=all&st=sim&where=post&start={pageNum}' html = urlopen(url) soup = bs(html, "html.parser") # 조건에 맞는 파일을 다 출력해라 title = soup.find_all(class_='sh_blog_title')
print(f'---{count}페이지 결과입니다 --------') for i in title: print(i.attrs['title']) print(i.attrs['href']) print() pageNum += 10 count += 1
from urllib.request import urlopen from bs4 import BeautifulSoup as bs from urllib.parse import quote_plus
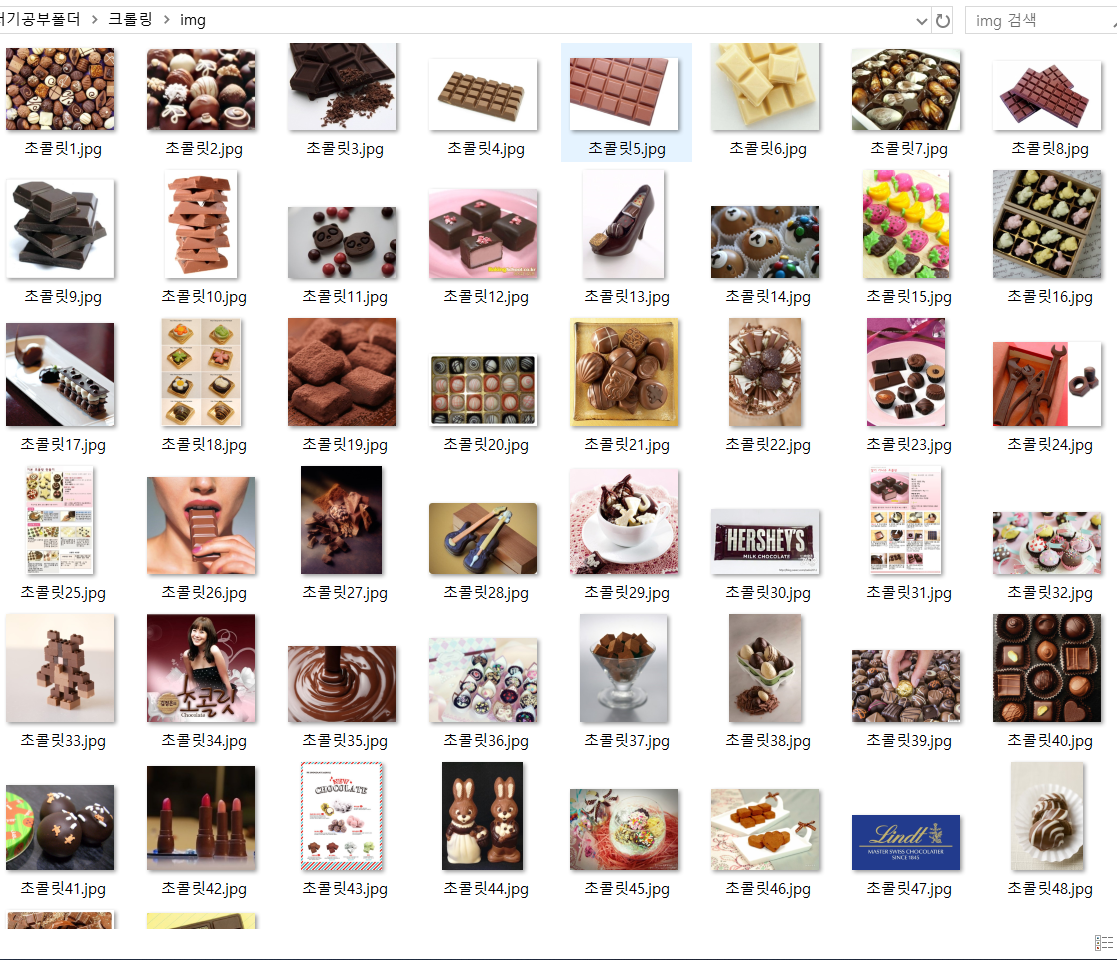
baseUrl = 'https://search.naver.com/search.naver?where=image&sm=tab_jum&query=' plusUrl = input('검색어를 입력하세요 : ') # 한글 검색 자동 변환 url = baseUrl + quote_plus(plusUrl) html = urlopen(url) soup = bs(html, "html.parser") img = soup.find_all(class_='_img')
n = 1 for i in img: imgUrl = i['data-source'] with urlopen(imgUrl) as f: withopen('./img/' + plusUrl + str(n)+'.jpg','wb') as h: # w - write b - binary img = f.read() h.write(img) n += 1 print('다운로드 완료')